1.
미국 HFT 스타트업을 준비하는 회사의 개발자가 블로그를 운영하고 있습니다. 여기에 Limit Order Book을 어떻게 디자인할 것인지를 올렸습니다.
How to build a fast limit order book
왜 이런 이야기를 할까요? 작년 dolppi님이 주최한 HFT RoundTable을 정리한 글을 간단히 옮깁니다.
현재 시스템 트레이딩은 시그널만 발생시키는 것이고, 한 종목에 대한 전략만 쓸 수 있어요. 체결을 받는다거나 할 수 없어서 order book 관리가 안되는데, 만약 order book을 보면서 진행되는 전략을 써야한다면 시스템 트레이딩으로는 불가능하죠.
HFT를 위한 시스템을 준비하면서 기술적 분석이 가능하도록 구성하려는 생각들이 있는것 같은데, 저는 두가지가 양립하기 어렵다고 봅니다. 일단은, 국내 HTS에서 제공하는 기술적 분석 도구들이 엄청 발전해있고 시스템도 꽤 큰 시스템이거든요. 이걸 단순히 증권사 내부 트레이딩 용으로 구축하기는 많이 힘들것 같구요. HFT는 좀 작은 시스템이라는 생각이 듭니다.
Strategy와 Order Book이 밀접히 관련이 있기때문에 블로그 운영자는 주요 이슈로 정리하였습니다. 여기까지는 별 문제가 없습니다.? 또다른 개발자가 위 블로그를 소개하면서 다음과 같은 주석을 달았습니다.
Fascinating blog on HFT implementation from WK. He commnts “a variation on this structure is to store the Limits in a sparse array instead of a tree. “ More detail on the implications for L1 and L2 cache behaviour of trees versus arrays for limits would be welcome. I’m assuming C++ implementation here of course, though WK points out you can make Java go fast if you avoid GC, which chimes with the experience of the LMAX guys. I ask because I interviewed with a big HFT firm last year: they gave me a programming exercise based on L1/2 cache behaviour.
Limit Order Book Implementation중에서
“A programming exercise based on L1/2 cache behaviour.” 이 문장때문에 L1/L2 Cache에 대한 조사를 하였습니다. IT동아에서 아주 쉽게 잘 정리한 글이 있더군요.
캐시 메모리(cache memory)란, 속도가 빠른 장치와 느린 장치 사이에서 속도 차에 따른 병목 현상을 줄이기 위한 범용 메모리를 말하는 것이다. CPU 이외의 장치에서도 많이 사용되는 용어인데, CPU에서는 CPU 코어(고속)와 메모리(CPU에 비해 저속) 사이에서 속도 차에 따른 병목 현상을 완화하는 역할을 한다.
CPU의 캐시메모리는 어떤 역할을 하는가중에서
그동안 프랍용 트레이딩시스템을 공급하던 회사들은 주문체결데이타를 관리하기 위하여 어떤 곳은 MMDBMS를, 어떤 회사는 Hash Table등을 사용하였습니다. 어떻게 제품과 기술로 구현하느냐에 따라 신규주문과 정정 및 쉬소주문을 처리할 때 속도차이가 있었습니다. 트레이딩시스템간 경쟁을 할 때 속도가 중요하기때문에 다양한 기술을 채택하려는 시도를 보았지만 컴퓨터구조로 접근한 경우를 한번도 보지 못했습니다. 그런데 L1/L2 Cache를 고려한 알고리즘을 사용하여 구현하여야 한다는 말을 하고 있습니다.
CPU와 메모리구조로 넘어가버렸습니다. 예전 나노초 측정을 다룰 때 OS 커널과 같습니다.
2.
좀더 깊이 들어가 보도록 하겠습니다. Kaist에서 강의 및 연구를 하신 분이 아주 멋진 글을 올려놓았습니다. 현대컴퓨터구조와 소프트웨어개개발과 관련한 내용입니다. 그중 앞서 다루었던 CPU,Cache등을 소개할 글이 있습니다. 현대 컴퓨터구조를 설명하는 이유를 다음과 같이 말합니다.
프로그램을 코딩할 때에 우리는 종종 컴퓨터 구조를 무시하거나, 망각하고 코딩하는 경우가 종종 있다. 이렇게 프로그래머들이 컴퓨터구조를 무시하는 이유는 내가 판단하기에 크게 두가지이다. 첫째는 잘 몰라 서이고, 둘째는 프로그래밍?생산성(productivity)을 증가시키기 위해 잘 추상화된, 즉 high-level abstraction을 제공하는 프로그래밍?언어의 사용 으로 인해서이다. 즉 프로그램 성능에 관한 문제를 완전히 또는 상당 부분 컴파일러나 인터프리터에게 맡겨버림으로써?더이상 컴퓨터 구조에 대한 고민을 하지 않아서이다. Java만 해도 포인터를 없앰으로써 메모리 관리에 대한 고민을 더이상 하지?않게 하지 않았는가? 이러한 프로그래밍 언어의 abstraction은 프로그램의 생산성은 크게 향상시켜 주었다. 하지만 프로그램의 성능(performance)에 대한 고민을 한다면, 저수준의 추상화를 제공하는 다른 프로그래밍 언어를 이용해 컴퓨터 구조에 잘맞는 프로그램의 작성이 요구될 것이다. 그리고 그것이 내가 생각하는 C/C++, Assembly가 아직도 성능이 우선시 되는 여러 프로그래밍 분야, 특히 시스템 프로그래밍에 널리 이용되는 이유이다.
Memory Hierarchy, Memory Wall and Memory Mountain중에서
이제 본격적으로 컴퓨터의 메모리구조에 대해 설명하고 있습니다. 아래의 그림으로 이해하시면 됩니다. 물론 깊은 내용은 위의 글을 읽어보시면 됩니다.
여기서 Cache Conscious 혹은 Cache Oblivious data structure라는 개념이 등장합니다. 역시나 같은 교수님의 주옥같은 글을 보도록 하죠.

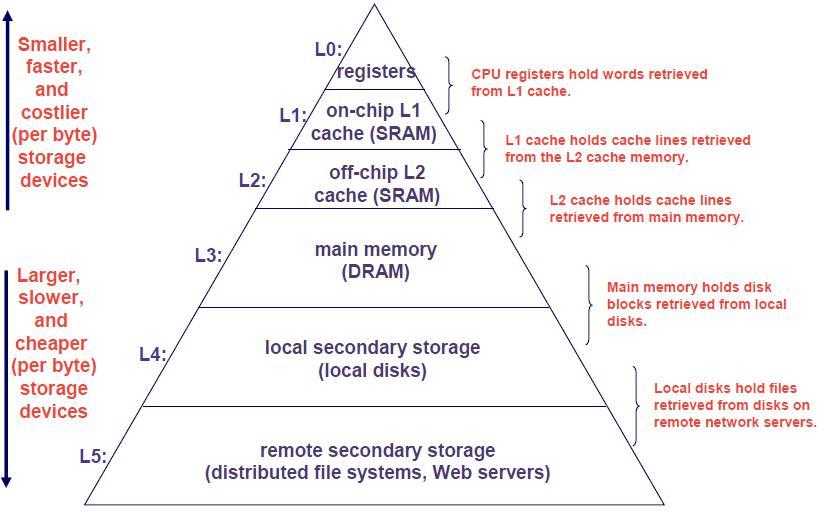
이전의 컴퓨터 시스템과 현재의 컴퓨터 시스템의 차이를 들자면, 여러가지가 있겠지만 현재까지 누적되어온 중요한 차이점들은 다음과 같다.
1) 더 커진 메모리 용량(capacity) 하지만 그만큼 개선되진 못한 접근속도(latency), 그리고 메모리 접근속도의 개선속도보다 더 빠르게 상승한 clock speed의 CPU. 그리고 이러한 접근속도의 차이에 의해 발생한 이에 따른 메모리 벽(memory wall) 문제 (메모리 벽 문제에 대해서는 일전에 올려둔 글을 참고하세요)
2) 더 커지고 계층화된 HW cache와 이에 따른 메모리 계층(memory hierarchy)
3) Supersclalar CPU(Out-of-Order Instruction Execution), branch prediction, SIMD, 그리고 SMT(Symmetric Multithreading)와 같은 CPU에서의 개선기능들.
4) Multicore(CMP; Chil-level MultiProcessor), Cell Processor, GPU등과 같이 달라진 구조의 CPU
5) Flash Memory
6) FPGA(Field Programmable Gate Array)즉, 현재의 시스템은 위와 같은 여러 추가적인 기능들을 제공하게 되는데, 기존의 코드들은 이러한 기능들을 제대로 이용하고 있지 않는다는 사실이다.그래서, 사람들은 Colume-oriented DBMS와 같은 data placement의 변경을 고안하기도 했으며,또한 메모리 벽 문제를 해결하기 위한 Cache-conscious와 Cache-oblivious algorithm들을 고안하였다.뿐만 아니라, CSB+-tree 처럼, B-tree와 같은 주요 자료구조들을 다시 바꾸기도 하였다. (Main-memory DBMS에서 이용하는 T-tree는 cache에 대한 고려가 전혀없는 구닥다리라나…) 또 칩 레벨의 멀티 프로세서를 지원하기 위한 여러 방법들이 고안되었고, GPU를 CPU 이외에 질의처리를 위한 보조 프로세서로 활용하기 위한 연구들도 2004년부터 소개되어왔다. 최근에는 I/O 비대칭성과 in-place update가 안되는, 하지만, latency와 요구전력이 HDD에 비해 월등히 낮은 Flash memory를 위한 여러 연구들도 진행되어 왔다.요새는 또 FPGA를 이용해 알고리즘을 HW로 구현하는 방식을 통해, 현재의 폰 노이만 방식의 컴퓨터 성능보다 몇십배 향상된 처리 성능을 보장하기도 한다.
DBMS on New Hardware중에서
위의 글중 “메모리 벽 문제를 해결하기 위한 Cache-conscious와 Cache-oblivious algorithm들을 고안하였다.”라는 문장입니다.
?이제 개발자들을 위하여 관련된 Cache-Conscious Data Structure와 관련된 논문과 소스를 소개하도록 하겠습니다. 위키를 찾아 보았지만 마땅한 자료를 보지 못했는데 이 논문은 훌룽한 듯 합니다. 논문을 평가할 능력이 없기때문에 그냥 짐작으로 말합니다.
Cache-conscious String Data Structures, Sorting and Algorithms: theory and practice
Nikolas Askitis교수가 발표한 논문과 소스를 보실 수 있습니다.
Efficient Data Structures For Cache Architecture
3.
우연히 시작한 하루동안의 조사를 마무리하였습니다. 제가 할 수 있는 일은 여기까지입니다.
HFT 혹은 Low Latency 아니면 알고리즘트레이딩을 쉽게 생각했습니다. 그렇지만 들어가면 갈수록 컴퓨터의 하드웨어와 소프트웨어, 특히 OS커널을 잘아는 엔지니어가 필요하다는 생각을 합니다. 앞으로의 트레이딩은 소프트웨어 엔지니어와 금융공학엔지니어들의 역량에 달렸습니다. ?어떤 트레이딩시스템을 설계하더라도 전략 + 트레이딩기술이 결합한 모양입니다.
주변을 살펴 봅니다. 금융회사에 다니든, 소프트웨어개발회사에 다니든 발전해야할 부분이 많습니다. 시니어 엔지니어는 책을 놓은지 오래라 새로운 기술과 변화를 받아드릴 역량이 부족합니다. 주니어 엔지니어는 는 도메인지식을 배워 빨리 ‘밥값’을 해야 하는 상황입니다. 더구나 금융소프트웨어를 하겠다는 ?자원하는 분들은 그저 개발자인 경우가 많습니다.
앞으로 트레이딩기술의 화두는 HPC와 Low Latency입니다. OS와 컴퓨터 하드웨어를 이해하는 엔지니어가 많아졌으면 합니다. KRX가 차차세대를 준비하고 있습니다. 하나의 전환점이 되었으면 합니다. 경쟁력있는 시스템을 국산기술로 개발하여 여타 기관과 회사에 많이 보급하였으면 좋겠습니다.이를 위해 KRX가 정보기술 Lap을 만들어 능력있는 엔지니어를 영입하면 어떨까 상상을 해봅니다.
마지막으로 레드햇에서 작성한 논문을 소개합니다. “개발자가 반드시 알아야 하는 메모리(What Every Programmer Should Know About Memory)”라는 제목입니다. ‘반드시’라는 단서가 붙었습니다.

좋은 내용 감사합니다. ^^
한자 남겨주셔서 감사드립니다. 지나가는 과객도 항상 환영합니다.
새해 복많이 받으세요..
잠깐 사족을 달자면.. Limit Order Book 에 관한 글은 사실 국내시장과는 좀 동떨어진 이야기입니다.
KRX에서는 각 투자자의 quote 를 모두 총합을 해서 10(5)호가의 order book 자체를 알려주지만 해외 거래소는 투자자의 quote packet 자체를 그냥 forwarding 해 주기 때문에 거래소 시스템 부하는 줄어도 개별 회원사나 투자자가 order book을 다시 재구성해야 합니다. 블로그에 나온 이야기는 그걸 위한 알고리즘 이야기인거 같습니다.
거래소와 브로커의 조건에 따라 설계와 개발을 하겠죠.
이 글에서 쓰고 싶었던 요지는 L1/L2 캐쉬를 이용한 데이타구조를 사용하고 있다는 점이었습니다. Low Latency와 관련된 제안준비를 하면서 수도 없이 겪었던 하드웨어에 최적화된 설계라는 말을 다시금 떠올라 소개하려고 했습니다.
굳이 비개발자인 제가 주절주절하지 않아도 다 잘알아서 하시고 있어.다른 관점만(^^)
새해 복많이 받으세요..자주 과천에 들린다는 이야기를 들었습니다.
좋은 글입니다.
상당수 개발자들이 웹서비스 관련 일들을 하면서 하드웨어 관점을 고려하지 않는 추세입니다.
PC나 서버베이스에서 개발을 해도 넉넉한 하드웨어 사양으로 코드 퍼포먼스는 거의 무시하는 경향이 크지요.
네트워크 프레임웍만 전담하는 사람이나 검색엔진 개발자가 아니면 ms 이하의 퍼포먼스는 고려도 안할겁니다.
그렇다고 모든 개발자가 그렇게 로우레벨까지 정통할 필요는 없다고 생각합니다.
자격을 갖춘 개발자라고 충분히 대우해 주는 사회도 아닌걸요 뭐.
모든 개발자는 아니라는 점 동의합니다.
현재 한국이 OS와 컴퓨터구조에 적통한 엔지니어가 대접받는 세상이 아니라는 점도 동의합니다.
다만 트레이딩이라고 할 경우. 직접 혹은 몇몇이 트레이딩을 하고자 할 경우 자신의 지식과 기술이 높으면 더 높은 수익을 얻을 확율은 높아지겠죠.
이도 저도 아니라고 하더라도 향후 트레이딩의 발전방향을 놓고 보면 낮은 수준의 학습과 경력을 쌓으면 길이 있으리라 생각합니다.
저의 지론.
공부해서 남 준 경우는 없다.(^^)
갑자기 한가한 제블로그에 유입수가 많아졌다 했더니…졸필을 인용해주셔서 감사합니다.
졸필이라고 생각하지 않습니다. 다른 사람들은 모르지만 저는 읽고 많은 도움을 받았습니다. 전후좌우맥락을 이해할 수 있도록 하려면 스스로 내공이 있어야 한다고 생각합니다. 감사합니다.
블로그에 방문하여 흔적 한번 길게 남기겠습니다.(^^)
건강하세요..
윽 뜨끔 하네요. 제가 OMS만들때 미체결주문내역을 Hash Table로 생성해서 처리 했었습니다. 대충 기억으로는 PJWHash 부터 시작해서 SDBHash까지 한 12종을 테스트해서 가장 빠르고, 자료구조와의 collision이 적은 방법을 찾는데 한참 시간을 투자 했었던 기억이 나네요..
코드 튜닝이 엄청나게 중요하지요. 한동안 주문순위가 꽤 높던(?) 프로그램이 느려졌다고 해서 불려가 보니,
생각해서 만들어 놓은 코드를 그곳직원이 로직추가한다고 죄 모듈화 시켜 놓았더군요.
stack콜 들어갔다 나갔다 하는걸 다 따져서 만들어 놓은건데..
주문쪽일이 참 재미있는게, 주문의 정당성과 증거금등을 체크 하고 거래소로 전송하는게 걸리는 시간을
0.1 ms 만 줄여도, 거래소에 접수되는 우선순위가 바뀌게 되고,
이에 따라 매매체결시스템에서 처리되는 주문의 처리시간만큼을 보상받습니다.
즉. 0.1ms, 100마이크로를 빠르게 해서 먼저 접수 시키면, 바로 0.1ms 뒤쳐져 들어온 주문 보다,
매매체결시스템의 종목큐에 등록되고, 반환되는 처리 시간이 2ms라고 한다면,
2ms의 응답을 먼저 받게 되는 것이지요. 0.1이 2.0으로 보상받는 상황이 벌어집니다.
http://blog.naver.com/daleena/100117162537
단순한 사례가 될지도 모르겠습니다만, 뭐 대충 GCC에서 옵티마이즈를 하는 이야기 입니다.
튜닝과 옵티마이즈의 길은 답도 없으면서 참 멀죠…
블로그를 방문해보니까 엔지니어로써의 열정이 느껴집니다.(^^)
저는 개발자가 아니라 이런저런 방법이 있다는 이야기만 하는 사람이라 시작만 도와줍니다. 사실 시작은 누구나 하지만 끝을 보는 사람은 몇 없죠. 개발에서도 역시 컴파일하고 시험을 하고 또 시험을 하고 해서 원하는 성능이 나도록 하는 사람이 끝을 보는 사람이겠죠. 그래서 멋진 개발자를 존경합니다.
쓰신 글중…
“매매체결시스템의 종목큐에 등록되고, 반환되는 처리 시간이 2ms라고 한다면,
2ms의 응답을 먼저 받게 되는 것이지요. 0.1이 2.0으로 보상받는 상황이 벌어집니다.”
의미심장합니다.
이래저래 저도 잘읽었습니다. 감사합니다.
좋은 글 잘 보았습니다.
최적화 하시느라 애 많이 쓰셨겠습니다.
그런데 인텔 플랫폼에서 성능향상을 꾀하고자 한다면, 자비가 들지 않는한 인텔 컴파일러 구입해서 쓰시는걸 강력하게 권장합니다.
경우에 따라 GCC보다 10~30% 정도 더 빠른 결과가 나오더군요.
그리고 이번에 “샌디브릿지” 모델이 새로 나왔죠.
이 녀석은 이제 SSE의 상위버전인 AVX를 사용하는데, SIMD 처리단위가 128bit에서 256bit로 두배가 늘었습니다.
서버용 칩은 코어가 최개 40개인 제품도 나올 예정이라는군요.
하드웨어 적인 이슈는 이런게 있고, 소프트웨어적으로는 ArBB라는 인텔에서 제공하는 오픈소스 라이브러리가 주목할만 합니다.
반복문 없이 한줄의 4칙연산 명령문으로 배열형식의 자료구조 데이터 연산이 가능해 집니다.
(AVX 한계 때문에 256bit 단위로 맞춰줘야 가장 좋은 성능이 나옵니다.)
도움이 되었으면 좋겠네요.
PS. 제가 있는 곳은 Only IBM + AIX 머신이라 인텔의 꼴리는 기술을 전혀 쓸 수가 없어 안타깝네요.
그나마 십수년전 하드웨어와 십수년전 운영체제라 컴파일도 버벅거리고 죽을 맛이네요. ㅡ ㅡ;
@PKT 다른 분들이 좋은 글을 블로그에 올렸기때문입니다. 저야 정리한 정도.
@성공을 꿈꾸는 개발자
저도 마켓데이타와 메시징을 개발하는 개발자에게 똑같은 이야기를 했습니다. 관련된 소스를 주면서 해보시라고 했더니 결과가 좋게 나왔다고 하네요. 하드웨어에 최적화된 바이너리가 아닐까 합니다.
하여튼 동감합니다.